
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- music data
- gan
- Phase Map 이미지
- Coherent Semantic Attention for Image Inpainting
- Phase Map
- CelebA
- 논문리뷰
- 2D 이미지 높이 측정
- Moire 이미지
- 백준
- 논문 리뷰
- Generative Adversarial Networks
- C-RNN-GAN:Continuous recurrent neural networkswith adversarial training
- AI 대회
- 이미지파일 특성으로 폴더분류
- labeling
- PAPER
- Python
- Generative Adversarial Nets
- json 파일로 image 라벨링
- 이미지 특징
- 자체 데이터 제작
- mnist
- 데이터 전처리
- json 파일 정보 csv파일로 저장
- Image Inpainting
- JSON
- 이미지 복원
- CT 영상에서 U-Net 기반 변형가능 컨볼루션 GAN을이용한 잡음제거
- horse2zebra
- Today
- Total
Deep Learning through deep learning
#1 논문리뷰 - Coherent Semantic Attention for Image Inpainting 본문
#1 논문리뷰 - Coherent Semantic Attention for Image Inpainting
NeuroN 2023. 8. 22. 11:36해당 논문링크
어느덧 대학 졸업을 앞두고 석사의 길로 발을 들이게 되었다.
어깨 너머로 박사님, 석사님 혹은 같은 인턴들을 여럿 보아오면서 기존의 공부 방식에 대한 고민을 하게 되었다.
딥러닝이라는 분야 속 이미지관련 영상처리 분야를 혼자 독학하기도 하고, 교수님의 지도를 받고, 비슷한 처지의 사람들의 조언을 받으면서 어찌어찌 공부를 해온 것이 지난 1년 6개월 부터이다.
그러던 와중에 이제는 프로그래밍의 구현 및 창조밖에 답이 없을까 싶은 시기에 비슷한 목표를 가진 석사형의 조언을 듣게 되었다.
논문을 읽으라는 것이었다.
그래서 논문을 읽어나가기로 한다. 첫 번째 논문은 현재 연구 주제에서 사용되는 모델로써 이미 여러차례 건드려보고 뒤늦게 세부적인 내용을 읽어나간다.
Topic
논문의 주제는 Coherent Semantic Attention for Image Inpainting 이다. 주제만을 보고 알 수 있는 점은 Image Inpainting 이라는 모델에 대해 기존의 연구와는 다른 차별성을 보여준다는 것 아닐까라고 대강 넘어간다.
Abstract
기존의 연구의 문제점을 말하고 넘어간다. 먼저 Inpainting 에 대해 짧게 짚고 넘어가면, 손상되거나 노이즈가 발생한 이미지에 대해 원래의 이미지로 복원하거나 원하는 물체 및 대상을 제거하여 재구성하는 등의 목적으로 구상된 알고리즘이라고 파악했다.
하지만 기존의 연구는 흐릿한 질감, 왜곡된 느낌 등 재구성한 이미지의 질적인 측면에서 아쉬움이 있었다.
그 이유는 local pixel 의 불연속성 때문이었으며, 노이즈나 손상된 부분의 의미적인 관련성이나 연속성 같은 것들을 무시하고 재구성하였기 때문이다.
기존 연구의 해결방안으로 해당 논문에서 CSA layer를 사용 및 제안한다.
결국 CSA layer가 논문의 핵심이자 전부이며, 이를 자세히 파악해야겠다고 생각했다.
해당 논문에서는 CSA layer를 통해 문맥적으로 의미적 관련성이나 연속성같은 것들을 잘 고려하여 재구성을 효과적으로 해준다고 말하고 있다.
논문에서 제시하는 전체적인 구조에 대해 짧게 소개하고 들어간다.
모델 구조는 크게 rough network, refinement network 로 나뉜다.
구조 속 사용된 신경망 구조는 U-Net 구조를 사용한다. (encoder-decoder 구조)
해당 논문에서 제시하는 CSA layer는 refinement network의 encoder안에 내장되어 있다.
추가적으로 학습 안정성을 위해 consistency loss 를 사용하고, feature patch discriminator를 통해 결과에 대한 디테일을 향상시킨다.
Introduction
기존의 연구들과 비교해 발전해온 과정과 더불어 논문에서 제시하는 아이디어가 나온 배경에 대해 설명한다.
기존의 연구는 손실된 영역 복원에 있어 의미론적 관계와 특징 연속성을 무시하기 때문에 좋은 결과를 얻지 못한다.
논문에서는 CSA layer를 통해 손실된 영역을 손실되지 않은 영역의 비슷한 패치로 복원하는 방법을 제시한다.
- rough network로 손실된 영역처리한다.
- refinement network의 CSA layer로 예측결과를 정재한다.
- 학습 과정을 더 안정적이고, 더 효율적으로 하기 위한 consistency loss를 손실함수로 사용한다.
- 결과의 디테일을 추가하기 위한 patch discriminator를 사용한다.
- loss는 총 consistency loss, reconstruction loss, relativistic average LS adversarial loss 세가지가 합쳐진 형태이다.
요약하자면, 구멍 영역의 깊은 특징 사이에서 상관관계를 구축하기 위해 CSA layer를 사용하였고, CSA 성능 향상과 훈련 안정성을 위해 consistency loss 제함으로써, 그 동안 feature patch discriminator는 더 나은 예측을 도와준다.
Approch
논문에서 제시하는 모델의 구조에 대한 설명이다.

- Rough Network 에서는 lgt (실제 이미지) 와 lin (손실된 이미지) 를 입력으로 하여, encoder-decoder 구조의 신경망을 통해 lp (대략적인 예측) 을 얻는다.
- 초기 입력 이미지는 256x256 크기를 디폴트로 한다.
- 신경망은 스킵 연결을 사용하는 4x4 컨볼루션으로 구성된다.
- GAN 생성 신경망으로 Pix2Pix 모델을 사용하였다.
- Refinement Network 에서는 lp와 lin을 다시 입력으로 하여, eoncoder-decoder 에 CSA layer를 추가한 신경망을 통해 lr (최종 예측) 을 얻는다.
- 신경망은 스킵 연결을 사용하는 3x3, 4x4 컨볼루션으로 구성된다.
- 3x3 컨볼루션 : 공간 크기 유지 + 채널 수 두배로 유지, 깊은 의미 정보를 얻는 능력 향상시킨다.
- 4x4 컨볼루션 : 공간 크기 절반 + 채널 수 유지, 과도한 정보 손실 방지한다.
- encoder의 네 번째 레이어에 CSA layer가 들어간다. decoder는 CSA layer 없이 encoder와 대칭 구조이다.
- Feature patch discriminator, Patch discriminator 를 통해 결과물 lr의 품질을 높인다.
- VGG-16 을 이용한다.
요약하자면, 두 개의 신경망 구조를 통해 손실된 이미지와 원본 이미지를 입력으로하여, 두 번에 걸친 적대적 신경망 훈련으로 손실된 영역을 고품질로 복원한다는 것이다.
핵심 부분인 CSA layer와 consistency loss에 대해 살펴보자면,

CSA layer의 작동 방식은 Mhat (회색영역) 알려진 영역과 M (파란영역) 손실되어 알려지지 않은 영역에 대해 알려지지 않은 영역을 알려진 영역으로 채워가는 방식이다.
Searching에서는 알려진 영역의 패치 m1hat, m2hat ... 의 가장 유사한 패치를 탐색하여 m1, m2 ... 패치로 결정한다. 이때 결정하는데 사용되는 가중치를 Dmaxi 로 하여 유사성을 검사한다.
Generating에서는 알려지지 않은 영역에 할당된 패치 m1, m2 ... 에 대해 가중치 Dadi 를 통해 인접한 패치 간의 유사성을 검사한다.
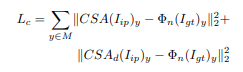
Consistency loss 의 경우 지각 손실 형태를 재설계하여, 일관성 손실을 제안한다.
사전 훈련된 VGG-16을 사용해 원본 이미지에서 고수준 피처 공간을 추출하고, M의 임의 위치에 대해 피처 공간을 CSA 레이어의 대상 및 디코더의 해당 레이어로 설정해 L2거리 계산한다.

DR은 GAN loss 이다.

Lre 는 원본 이미지 (lgt) 와 예측한 결과 이미지 (lp,lr) 간의 차이값의 합으로 구성되어 있다. 원본과 얼마나 유사한지 정도를 나타낸다고 이해했다.

최종적으로 위희 3 loss를 합한 형태로 손실함수가 정의된다. 람다값은 파라미터이다.
Experiments
해당 깃허브 링크
https://github.com/KumapowerLIU/CSA-inpainting?files=1
논문에서 진행한 실험을 토대로 github 링크를 통해 직접 훈련 및 결과를 확인하였다.
논문에서는 마스크 이미지를 무작위로 설정해주거나, 사각형으로 설정해주었다. 이 코드 부분을 수정하여 원하는 형태의 마스크를 생성하도록 하였다.



왼쪽부터 차례대로 원본이미지, 마스크 영역에 대한 이미지, 손실된 이미지로 설정하였다.
손실된 이미지를 살펴보면 사각형과 원에 대해 그림자처럼 늘어진 것을 확인할 수 있다. 이러한 부분을 마스크로 가려 원본이미지처럼 재구성하고자 하였다.
마스크를 형성하는 과정에 Mopology 를 통해 필요없는 부분은 지우고 마스크 영역은 조금 확대하였다.



왼쪽부터 차례대로 손실된 이미지, 마스크 이미지, 결과 이미지이다.
손실된 이미지에 대해 마스크 영역으로 마스크를 씌웠고, 훈련된 모델에 넣고 이미지를 재구성하였다.
결과 이미지를 확인해보면 그림자처럼 늘어진 영역이 눈에 띄게 복원된 것을 확인할 수 있다.
하지만, 마스크 영역에 대한 더 정확한 기준과 모델의 경량화 작업이 들어가지 않아 높은 성능을 보여주지 못하는 것을 확인할 수 있다.
else
글을 통해 알 수 있듯이 첫 번째 논문 리뷰는 사실상 연구 주제를 위한 논문 리뷰 및 실습이었다.
두 번째부터는 아마도 실직적인 논문 리뷰 및 비교적 간단한 논문 리뷰부터 시작할 생각이다.
본 논문에서는 손실된 이미지 복원이라는 목적이었지만, 이를 응용하여 원하는 영역 재구성으로 활용 및 실습해보았다.
'ML&DL > Paper Review (논문)' 카테고리의 다른 글
| #4 논문 리뷰 - C-RNN-GAN:Continuous recurrent neural networkswith adversarial training (1) | 2023.08.28 |
|---|---|
| #3 논문리뷰 - Generative Adversarial Nets (3) | 2023.08.24 |
| #2 논문리뷰 - CT 영상에서 U-Net 기반 변형가능 컨볼루션 GAN을이용한 잡음제거 (0) | 2023.08.22 |


