
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Python
- 이미지 특징
- labeling
- json 파일로 image 라벨링
- horse2zebra
- AI 대회
- 데이터 전처리
- JSON
- Coherent Semantic Attention for Image Inpainting
- Moire 이미지
- Phase Map
- Phase Map 이미지
- Generative Adversarial Nets
- CT 영상에서 U-Net 기반 변형가능 컨볼루션 GAN을이용한 잡음제거
- 2D 이미지 높이 측정
- 자체 데이터 제작
- Image Inpainting
- CelebA
- json 파일 정보 csv파일로 저장
- music data
- 백준
- 이미지 복원
- C-RNN-GAN:Continuous recurrent neural networkswith adversarial training
- 논문리뷰
- 이미지파일 특성으로 폴더분류
- mnist
- Generative Adversarial Networks
- gan
- 논문 리뷰
- PAPER
- Today
- Total
Deep Learning through deep learning
#4 CycleGAN - PCB (자체 데이터 이용) 본문
GAN에 대해 실습을 통해 어느정도 시각적으로 이해가 되었으리라 생각한다.
제목을 보고 갑작스럽게 넘어가는것에 대해 당황 할 수도 있으리라 생각하지만, DCGAN 이후 등장하는 CGAN > Pix2Pix 모델같은 경우에는 단순 조건 추가이거나, 한 쌍의 이미지가 필요하듯이 제한적인 요소가 많다.
자체적으로 데이터를 만들어 확실한 결과를 뽑기 위해선 이 두 단계의 모델을 건너뛰고자 한다. (물론 이 글을 읽는 분들은 이미 두 모델에 대한 이론적 지식이 충분할 것이라고 생각한다.)
CycleGAN에서는 초기 GAN을 소개할 때 언급했던 이미지 복원이라는 목표를 가능하게 한다.
서론이 길었으니 일단 이론부터 살펴보자.
Theory
DCGAN 이후의 모델에 대한 세 줄 요약 들어가겠다.
- CGAN - 라벨 정보를 추가하여 (또는 클래스 정보), 이전의 이미지 생성에만 그치지 않고 해당 클래스에 대한 무작위 스타일의 이미지 생성이 가능하다.
- Pix2Pix - 한 쌍의 이미지를 사용하여, 무작위가 아닌 원하는 스타일을 입힌 이미지 생성이 가능하다.
- CycleGAN - 기존의 이미지 데이터셋과 스타일을 입히고자 하는 아무 이미지 데이터셋 두 종류만 가지고 원하는 스타일 이미지 생성이 가능하다.
- 위에서 하고자 하는 말은 결국 순수한 이미지 생성은 GAN에서 그친 것이다. 스타일을 입힌 이미지 생성은 CGAN부터 시작하여 CycleGAN까지 (물론 더 최신의 모델이 있으나 연구 주제는 CycleGAN 만으로 충분하였다.) 발전되어왔고 이전의 모델이 구조적으로 이해가 쉬우나, 우리의 목표는 활용에 있다는걸 다시한번 강조하고자 CycleGAN 으로 시작하고자 한다.
CycleGAN 을 활용하기 위한 특징에 대해 알고가자.
- 위에서 말했듯이 두 종류의 데이터셋이 필요하다. 대표적인 예로써 말을 얼룩말처럼 무늬를 입히고자 한다.
- 이때 말은 A이미지 데이터셋이라고 할 수 있고, 얼룩말은 B이미지 데이터셋이라고 할 수 있으며, 무늬를 입힌다는 것은 스타일을 적용한다고 생각할 수 있다.
- 즉, 우리는 A라는 이미지 데이터셋을 기준으로 B라는 이미지 데이터셋의 스타일을 A에게 입히고자 할 때 사용할 수 있다.
- 모델의 구조도 이전과 많이 달라진다. 하지만 우리가 알아야하는건 Discriminator와 Generator가 한 쌍이 아닌 두 쌍이 된다는 것이다.
- 직관적으로 생각하면 데이터셋 종류가 두 배가 되었으니 모델도 두 배가 된다고 생각할 수 있다.
- 간략하게 설명하자면, A에서 B로 B에서 A로 이미지의 변환이 둘 다 가능해야하기 때문이다.
Using GAN
- 말 to 얼룩말
- 이 글에서는 간단하게 말에서 얼룩말로 스타일 입히는 예제를 돌려보는 것으로 시작한다.
- 물론 데이터는 다운받아서 사용함으로써 데이터셋 구성에 대해 이해하고 넘어가야한다.
- 손상된 PCB to 원본 PCB
- 이후 스타일을 입힌다는 개념을 꼬아 이미지를 복원한다는 개념으로 적용해보고자 한다.
- 원하는 스타일을 입힌다는 것은 이미지의 원하는 부분을 바꿀 수 있다는 것이고, 원하는 부분을 바꾼다는 것은 손실된 부분을 원래대로 복원할 수 있지 않겠느냐는 생각이다.
Coding GAN
CycleGAN (말 & 얼룩말 데이터셋) 을 통한 스타일 변화
TRAIN 과정
1. 필요한 모듈 import
import os
import glob
import random
import itertools
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
import time
import numpy as np
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy import asarray
from numpy.random import shuffle
from scipy.linalg import sqrtm
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.datasets.mnist import load_data
from skimage.transform import resize
from keras.datasets import cifar10
import cv2> 없다면 pip 명령어로 install (혹은 conda)
2. 아래의 사이트에서 말 & 얼룩말 이미지 데이터셋을 다운로드 받는다.
!wget https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/horse2zebra.zip -- '0'> 해당 사이트에서 데이터셋의 zip 파일을 다운받아 현재 작업위치에 저장된다. (아나콘다의 경우 아나콘다의 파이썬 파일이 만들어진 위치에 저장된다.)
%%capture
!unzip ./horse2zebra.zip -d ./> 해당 zip 파일이 다운로드 된 경로를 unzip 경로에 넣고 압축해제한다.
!mkdir -p "horse2zebra/train"
!mkdir -p "horse2zebra/test"
!mv "horse2zebra/trainA" "horse2zebra/train/trainA"
!mv "horse2zebra/trainB" "horse2zebra/train/trainB"
!mv "horse2zebra/testA" "horse2zebra/test/testA"
!mv "horse2zebra/testB" "horse2zebra/test/testB"> horse2zebra 폴더 안에 train / test 폴더를 만들어주고, 하위폴더로 각각 trainA / trainB 이미지 데이터셋, testA / testB 이미지 데이터셋을 옮겨준다.
즉, horse2zebra 라는 최상단 폴더 속에 train / test 폴더가 들어있다.
train 폴더에는 trainA / trainB 폴더가 위치하고, test 폴더에는 testA / testB 폴더가 위치한다.
여기서 핵심은 A,B 가 앞서 말한 A 이미지 데이터셋과 B이미지 데이터셋을 말한다.
3. 이제 데이터셋 전처리에 들어간다.
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/trainA") + "/*.jpg"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/trainB") + "/*.jpg"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))> 이미지 데이터셋 전처리 및 불러오기 위한 코드이다.
to_rgb 에서 이미지를 RGB 채널 이미지로 변환해준다. (컬러 이미지인 경우에만)
ImageDataset을 살펴보면,
init 에서는, horse2zebra 폴더 경로가 입력되면 train 폴더를 찾고, trainA / trainB 의 jpg 형식 이미지를 각각 files_A, files_B 에 파일명으로 저장한다.
getitem 에서는, 해당 파일속에서 이미지를 불러와 RGB로 채널 변환 후 이미지 A,B를 각각 return 해준다.
len 에서는, 이미지폴더 속 이미지 데이터 개수를 return 해준다.
class ImageDataset2(Dataset):
def __init__(self, root, transforms_=None, mode="test"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/testA") + "/*.jpg"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/testB") + "/*.jpg"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))> test 데이터도 마찬가지로 설정
transforms_ = transforms.Compose([
transforms.Resize(int(256), Image.BICUBIC), # 이미지 크기를 조금 키우기
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset1 = ImageDataset("./horse2zebra", transforms_=transforms_)
val_dataset = ImageDataset2("./horse2zebra", transforms_=transforms_)
train_dataloader1 = DataLoader(train_dataset1, batch_size=1, shuffle=True, num_workers=1)
val_dataloader = DataLoader(val_dataset, batch_size=1, shuffle=True, num_workers=1)> 정의한 함수로 데이터셋 불러오는 코드이다.
transforms_ 에서는, 이미지 크기를 조정하고, 정규화한다. (이미지 증강을 위해 뒤집고 돌릴 수 있으나 이는 참고하여 추가해주길 바란다.)
train / test 데이터셋을 불러와주고 배치사이즈, 섞을 여부, 일꾼 개수를 지정한다.
준비된 데이터셋 horse2zebra의 경로는 ' ' 안에 넣어주자.
# 잔여 블록(Residual Block) 모듈 정의
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
nn.ELU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x)
# ResNet 기반의 생성자(Generator) 아키텍처
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0] # 입력 이미지의 채널 수: 3
out_channels = 64
model = [nn.ReflectionPad2d(channels)]
model.append(nn.Conv2d(channels, out_channels, kernel_size=7))
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 다운샘플링(Downsampling)
for _ in range(2):
out_channels *= 2
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)) # 너비와 높이가 2배씩 감소
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 감소한 높이) X (4배 감소한 너비)]
# 인코더와 디코더의 중간에서 Residual Blocks 사용 (차원은 유지)
for _ in range(num_residual_blocks):
model.append(ResidualBlock(out_channels))
# 업샘플링(Upsampling)
for _ in range(2):
out_channels //= 2
model.append(nn.Upsample(scale_factor=2)) # 너비와 높이가 2배씩 증가
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)) # 너비와 높이는 그대로
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 증가한 높이) X (4배 증가한 너비)]
# 출력 콘볼루션 블록(Convolution Block) 레이어
model.append(nn.ReflectionPad2d(channels))
model.append(nn.Conv2d(out_channels, channels, kernel_size=7))
model.append(nn.Tanh())
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# 콘볼루션 블록(Convolution Block) 모듈 정의
def discriminator_block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1)] # 너비와 높이가 2배씩 감소
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.ELU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False), # 출력: [64 X 128 X 128]
*discriminator_block(64, 128), # 출력: [128 X 64 X 64]
*discriminator_block(128, 256), # 출력: [256 X 32 X 32]
*discriminator_block(256, 512), # 출력: [512 X 16 X 16]
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, kernel_size=4, padding=1) # 출력: [1 X 16 X 16]
)
# 최종 출력: [1 X (16배 감소한 높이) X (16배 감소한 너비)]
def forward(self, img):
return self.model(img)> Generator 생성기와 Discriminator 판별기 함수를 정의해주는 코드이다.
구조는 CycleGAN 이론을 참고하길 바란다. 추가적으로 바꾼건 Activation Function 에서 ReLU함수를 ELU 함수로 바꾼 정도이다.
# 생성자(generator)와 판별자(discriminator) 초기화
G_AB = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
G_BA = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
D_A = Discriminator(input_shape=(3, 256, 256))
D_B = Discriminator(input_shape=(3, 256, 256))
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
# 가중치 초기화를 위한 함수 정의
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
# 모델을 훈련시키고 저장이후 이어서 훈련을 진행하기 위해 해당 위치에 주석을 풀고 저장한 모델가중치파일 경로를 넣으면 된다.
'''
G_AB.load_state_dict(torch.load("./model_AB.pt"))
G_BA.load_state_dict(torch.load("./model_BA.pt"))
D_A.load_state_dict(torch.load("./model_A.pt"))
D_B.load_state_dict(torch.load("./model_B.pt"))
'''> G,D 를 정의 및 가중치 초기화를 해주는 코드이다.
위 이론에서 G,D 가 각각 2개씩 필요하다고 언급했고 우리는 이 4개의 신경망을 일일이 초기화 해준다.
G,D 초기화에 있어서 입력 크기를 지정해주고, GPU를 할당해준다.
가중치 초기화에 있어서 함수를 정의하고 각각의 신경망에 할당한다.
주석으로 처리된 load_state_dict는 저장한 모델의 가중치를 불러와 학습을 이어서 진행할 수 있다.
# 이미지 배열을 새로운 크기로 바꾸기
def scale_images(images, new_shape):
images_list = list()
for image in images:
# resize with nearest neighbor interpolation
new_image = resize(image, new_shape, 0)
# store
images_list.append(new_image)
return asarray(images_list)
# frechet inception distance GAN 평가 지표를 통해 정확도 계산
def calculate_fid(model, images1, images2):
# calculate activations
act1 = model.predict(images1)
act2 = model.predict(images2)
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
# 이미지 버퍼(Buffer) 클래스
class ReplayBuffer:
def __init__(self, max_size=50):
self.max_size = max_size
self.data = []
# 새로운 이미지를 삽입하고, 이전에 삽입되었던 이미지를 반환하는 함수
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
# 아직 버퍼가 가득 차지 않았다면, 현재 삽입된 데이터를 반환
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
# 버퍼가 가득 찼다면, 이전에 삽입되었던 이미지를 랜덤하게 반환
else:
if random.uniform(0, 1) > 0.5: # 확률은 50%
i = random.randint(0, self.max_size - 1)
to_return.append(self.data[i].clone())
self.data[i] = element # 버퍼에 들어 있는 이미지 교체
else:
to_return.append(element)
return torch.cat(to_return)
# 시간이 지남에 따라 학습률(learning rate)을 감소시키는 클래스
class LambdaLR:
def __init__(self, n_epochs, decay_start_epoch):
self.n_epochs = n_epochs # 전체 epoch
self.decay_start_epoch = 200 # 학습률 감소가 시작되는 epoch
def step(self, epoch):
return 1.0 - max(0, epoch - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)> 학습에 필요한 나머지 함수들을 정의하는 코드이다.
scale_images 에서 이후 학습을 진행하면서 생성된 이미지를 시각화하기 위해 함수로 정의한다.
calculate_fid 에서 실제 이미지와 생성된 이미지 간의 유사도를 통해 GAN 정확도 지표라 불리는 함수를 정의한다.
LambdaLR 에서 학습을 진행하면서 학습률을 감소시켜 최적의 학습률을 구하기위해 함수로 정의한다.
# 손실함수 초기화
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
n_epochs = 100000000 # 학습의 횟수(epoch) 설정
decay_epoch = 100 # 학습률 감소가 시작되는 epoch 설정
lr = 0.0002 # 초기 학습률(learning rate) 설정
# 옵티마이저 초기화
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(0.5, 0.999))
# 학습률(learning rate) 업데이트 스케줄러 초기화
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
sample_interval = 100 # 몇 번의 배치(batch)마다 결과를 출력할 것인지 설정
model2 = InceptionV3(include_top=False, pooling='avg', input_shape=(256,256,3))
FFID = 100
lambda_cycle = 10 # Cycle 손실 가중치(weight) 파라미터
lambda_identity = 5 # Identity 손실 가중치(weight) 파라미터
# 이전에 생성된 이미지 데이터를 포함하고 있는 버퍼(buffer) 객체
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
start_time = time.time()> 파라미터를 정의하는 코드이다.
손실함수의 경우, 이론에 따르면 3가지의 손실함수를 사용하고 위와 같이 정의 및 GPU 할당을 해준다.
n_epochs 로 학습 횟수를 정하는데 학습과정에서 모델을 수시로 저장하기 때문에 중간에 커널을 종료해도 상관없기에 큰 수로 할당하였다.
decay_epoch 에서는 위에 정의한 학습률 감소를 어느 지점에서 진행할지에 대한 변수이다.
lr 에서는 학습률을 초기에 몇으로 정할지에 대한 변수이다.
옵티마이저의 경우 G_AB, G_BA 를 묶고, D_A, D_B (총 4개의 신경망) 에 대해 Adam 옵티마이저를 취한다.
학습률 감소를 위해 scheduler 초기화도 해준다.
sample_interval 에서는 모델 저장 및 생성 이미지 결과 저장을 어느 지점에서 진행할지에 대한 변수이다.
model2 를 새로 정의한 이유는 FID 계산을 위해 InceptionV3 모델을 불러와야하기 때문이다.
FFID 에서는 FID 가 최소가 되는 즉, 최적화된 모델만을 저장하기 위해 FID 최솟값을 구하기 위한 변수이다.
나머지 파라미터는 따로 변경할 필요는 없으니 주석을 통해 참고하길 바란다.
for epoch in range(n_epochs):
for i, batch in enumerate(train_dataloader_1):
# 모델의 입력(input) 데이터 불러오기
real_A = batch["B"].cuda()
real_B = batch["A"].cuda()
# 진짜(real) 이미지와 가짜(fake) 이미지에 대한 정답 레이블 생성 (너비와 높이를 16씩 나눈 크기)
real = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(1.0) # 진짜(real): 1
fake = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(0.0) # 가짜(fake): 0
############## 생성자(generator) 학습 ##############
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity 손실(loss) 값 계산
loss_identity_A = criterion_identity(G_BA(real_A), real_A)
loss_identity_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_identity_A + loss_identity_B) / 2
# GAN 손실(loss) 값 계산
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
loss_GAN_AB = criterion_GAN(D_B(fake_B), real)
loss_GAN_BA = criterion_GAN(D_A(fake_A), real)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle 손실(loss) 값 계산
recover_A = G_BA(fake_B)
recover_B = G_AB(fake_A)
loss_cycle_A = criterion_cycle(recover_A, real_A)
loss_cycle_B = criterion_cycle(recover_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# 최종적인 손실(loss)
loss_G = loss_GAN + lambda_cycle * loss_cycle + lambda_identity * loss_identity
# 생성자(generator) 업데이트
loss_G.backward()
optimizer_G.step()
############## 판별자(discriminator) A를 학습 ##############
optimizer_D_A.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_A(real_A), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_A = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A.detach()), fake)
# 최종적인 손실(loss)
loss_D_A = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_A.backward()
optimizer_D_A.step()
############## 판별자(discriminator) B를 학습합니다. ##############
optimizer_D_B.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_B(real_B), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_B = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B.detach()), fake)
# 최종적인 손실(loss)
loss_D_B = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
done = epoch * len(train_dataloader_1) + i
############## 결과 저장 ##############
if done % sample_interval == 0:
G_AB.eval()
G_BA.eval()
imgs = next(iter(val_dataloader)) # 5개의 이미지를 추출해 생성
real_A = imgs["B"].cuda()
real_B = imgs["A"].cuda()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
# X축을 따라 각각의 그리디 이미지 생성
real_A = make_grid(real_A, normalize=True)
real_B = make_grid(real_B, normalize=True)
fake_A = make_grid(fake_A, normalize=True)
fake_B = make_grid(fake_B, normalize=True)
save_image(fake_A, f"./fake_A.png", normalize=False)
# 말 > 얼룩말로 바꾼 생성된 이미지
save_image(real_B, f"./real_B.png", normalize=False)
# 말 원본 이미지
# convert integer to floating point values
fake_B = fake_B.cpu().numpy()
real_B = real_B.cpu().numpy()
fake_B = fake_B.astype('float32')
real_B = real_B.astype('float32')
# resize images
fake_B = scale_images(fake_B, (256,256,3))
real_B = scale_images(real_B, (256,256,3))
#print('Scaled', fake_B.shape, real_B.shape)
# pre-process images
fake_B = preprocess_input(fake_B)
real_B = preprocess_input(real_B)
'''
# calculate fid
fid = calculate_fid(model2, fake_B, real_B)
if FFID > fid:
FFID = fid
print('FID: %.3f' % fid)
'''
torch.save(G_AB.state_dict(), f"./model_AB.pt")
torch.save(G_BA.state_dict(), f"./model_BA.pt")
torch.save(D_A.state_dict(), f"./model_A.pt")
torch.save(D_B.state_dict(), f"./model_B.pt")
print("Model 갱신!")
# 학습률(learning rate)
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
print(f"[Epoch {epoch}/{n_epochs}] [Elapsed time: {time.time() - start_time:.2f}s]")> 학습 과정에 대한 코드이다.
학습 과정은 자세히 다루지 않겠지만 주석 내용으로 이론을 바탕이면 어느정도 감을 잡으리라 생각한다.
결과 저장 부분이 핵심인데, 우리가 원하는건 말의 원본이미지에서 얼룩말로 생성된 이미지를 보기 위함이니 이 두 이미지 (fake_A, real_B)를 저장해준다.
이후 FID를 계산은 주석으로 처리하였다. 이후 자체 데이터셋에 이용될 예정이지만, 예제 데이터셋에서는 사용할 필요가 없기 때문에 잠시 보류해두겠다.
torch.save 를 통해 모델의 가중치만 저장한다. (형식은 반드시 .pt)
이후 학습률이 업데이트되면서 epoch가(학습이) 진행될 때마다 epoch와 시간을 함께 띄워준다.


학습을 얼마 하지 않은 결과 사진이다. (왼쪽이 원본이미지 real_B, 오른쪽이 생성된 이미지 fake_A)
TEST 과정
# 필요 모듈 import
import os
import glob
import random
import itertools
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy import asarray
from numpy.random import shuffle
from scipy.linalg import sqrtm
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.datasets.mnist import load_data
from skimage.transform import resize
from keras.datasets import cifar10
# 함수 및 클래스 정의
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset2(Dataset):
def __init__(self, root, transforms_=None, mode="test"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/testA") + "/*.jpg"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/testB") + "/*.jpg"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
transforms_ = transforms.Compose([
transforms.Resize(int(256), Image.BICUBIC), # 이미지 크기를 조금 키우기
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 데이터 불러오기
val_dataset1 = ImageDataset2("./horse2zebra", transforms_=transforms_)
val_dataloader1 = DataLoader(val_dataset1, batch_size=1, shuffle=False, num_workers=1)
# 잔여 블록(Residual Block) 모듈 정의
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
# 채널(channel) 크기는 그대로 유지
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
nn.ELU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x)
# ResNet 기반의 생성자(Generator) 아키텍처
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0] # 입력 이미지의 채널 수: 3
# 초기 콘볼루션 블록(Convolution Block) 레이어
out_channels = 64
model = [nn.ReflectionPad2d(channels)]
model.append(nn.Conv2d(channels, out_channels, kernel_size=7))
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 다운샘플링(Downsampling)
for _ in range(2):
out_channels *= 2
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)) # 너비와 높이가 2배씩 감소
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 감소한 높이) X (4배 감소한 너비)]
# 인코더와 디코더의 중간에서 Residual Blocks 사용 (차원은 유지)
for _ in range(num_residual_blocks):
model.append(ResidualBlock(out_channels))
# 업샘플링(Upsampling)
for _ in range(2):
out_channels //= 2
model.append(nn.Upsample(scale_factor=2)) # 너비와 높이가 2배씩 증가
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)) # 너비와 높이는 그대로
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 증가한 높이) X (4배 증가한 너비)]
# 출력 콘볼루션 블록(Convolution Block) 레이어
model.append(nn.ReflectionPad2d(channels))
model.append(nn.Conv2d(out_channels, channels, kernel_size=7))
model.append(nn.Tanh())
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# 콘볼루션 블록(Convolution Block) 모듈 정의
def discriminator_block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1)] # 너비와 높이가 2배씩 감소
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.ELU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False), # 출력: [64 X 128 X 128]
*discriminator_block(64, 128), # 출력: [128 X 64 X 64]
*discriminator_block(128, 256), # 출력: [256 X 32 X 32]
*discriminator_block(256, 512), # 출력: [512 X 16 X 16]
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, kernel_size=4, padding=1) # 출력: [1 X 16 X 16]
)
# 최종 출력: [1 X (16배 감소한 높이) X (16배 감소한 너비)]
def forward(self, img):
return self.model(img)
# 시간이 지남에 따라 학습률(learning rate)을 감소시키는 클래스
class LambdaLR:
def __init__(self, n_epochs, decay_start_epoch):
self.n_epochs = n_epochs # 전체 epoch
self.decay_start_epoch = decay_start_epoch # 학습률 감소가 시작되는 epoch
def step(self, epoch):
return 1.0 - max(0, epoch - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
# 생성자(generator)와 판별자(discriminator) 초기화
G_AB = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
G_BA = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
D_A = Discriminator(input_shape=(3, 256, 256))
D_B = Discriminator(input_shape=(3, 256, 256))
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
G_AB.load_state_dict(torch.load("./model_AB.pt"))
G_BA.load_state_dict(torch.load("./model_BA.pt"))
D_A.load_state_dict(torch.load("./model_A.pt"))
D_B.load_state_dict(torch.load("./model_B.pt"))
G_AB.eval();
G_BA.eval();
D_A.eval();
D_B.eval();
# 손실 함수(loss function)
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
n_epochs = 200 # 학습의 횟수(epoch) 설정
decay_epoch = 5 # 학습률 감소가 시작되는 epoch 설정
lr = 0.0002 # 학습률(learning rate) 설정
# 생성자와 판별자를 위한 최적화 함수
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(0.5, 0.999))
# 학습률(learning rate) 업데이트 스케줄러 초기화
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
max_acc = 0
i = 0
# scale an array of images to a new size
def scale_images(images, new_shape):
images_list = list()
for image in images:
# resize with nearest neighbor interpolation
new_image = resize(image, new_shape, 0)
# store
images_list.append(new_image)
return asarray(images_list)
# calculate frechet inception distance
def calculate_fid(model, images1, images2):
# calculate activations
act1 = model.predict(images1)
act2 = model.predict(images2)
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
while(1):
if i == 1:
break
e = 0
from PIL import Image
imgs = next(iter(val_dataloader1))
real_A = imgs["B"].cuda()
real_B = imgs["A"].cuda()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
fake_B = make_grid(fake_B, normalize=True)
real_B = make_grid(real_B, normalize=True)
fake_A = make_grid(fake_A, normalize=True)
real_A = make_grid(real_A, normalize=True)
save_image(fake_B, f"./fake_B.jpg", normalize=False)
save_image(real_B, f"./real_B.jpg", normalize=False)
save_image(fake_A, f"./fake_A.jpg", normalize=False)
save_image(real_A, f"./real_A.jpg", normalize=False)
'''
model2 = InceptionV3(include_top=False, pooling='avg', input_shape=(256,256,3))
print('Loaded', fake_B.shape, real_B.shape)
# convert integer to floating point values
fake_B = fake_B.cpu().numpy()
real_B = real_B.cpu().numpy()
fake_B = fake_B.astype('float32')
real_B = real_B.astype('float32')
# resize images
fake_B = scale_images(fake_B, (256,256,3))
real_B = scale_images(real_B, (256,256,3))
print('Scaled', fake_B.shape, real_B.shape)
# pre-process images
fake_B = preprocess_input(fake_B)
real_B = preprocess_input(real_B)
# calculate fid
fid = calculate_fid(model2, fake_B, real_B)
print('FID: %.3f' % fid)
'''
i+=1> 경로만 수정하여 사용하면 된다.
저장한 모델 및 데이터셋 경로를 수정하여 코드를 돌리면, 원본이미지부터 생성된 이미지까지 총 4장의 이미지가 출력된다.
CycleGAN (손상된 이미지 & 원본 이미지 데이터셋) 을 통한 이미지 복원
데이터셋 구성
데이터셋 구성은 다음과 같다.

> 손상된 이미지 trainB이다. 큰 직사각형 판을 PCB라고 한다면, 검은 직사각형 및 원을 소자라고 할 수 있다. 소자마다 회식의 그림자를 가지고 있고 이 그림자를 제거하여 복원하고자 한다.
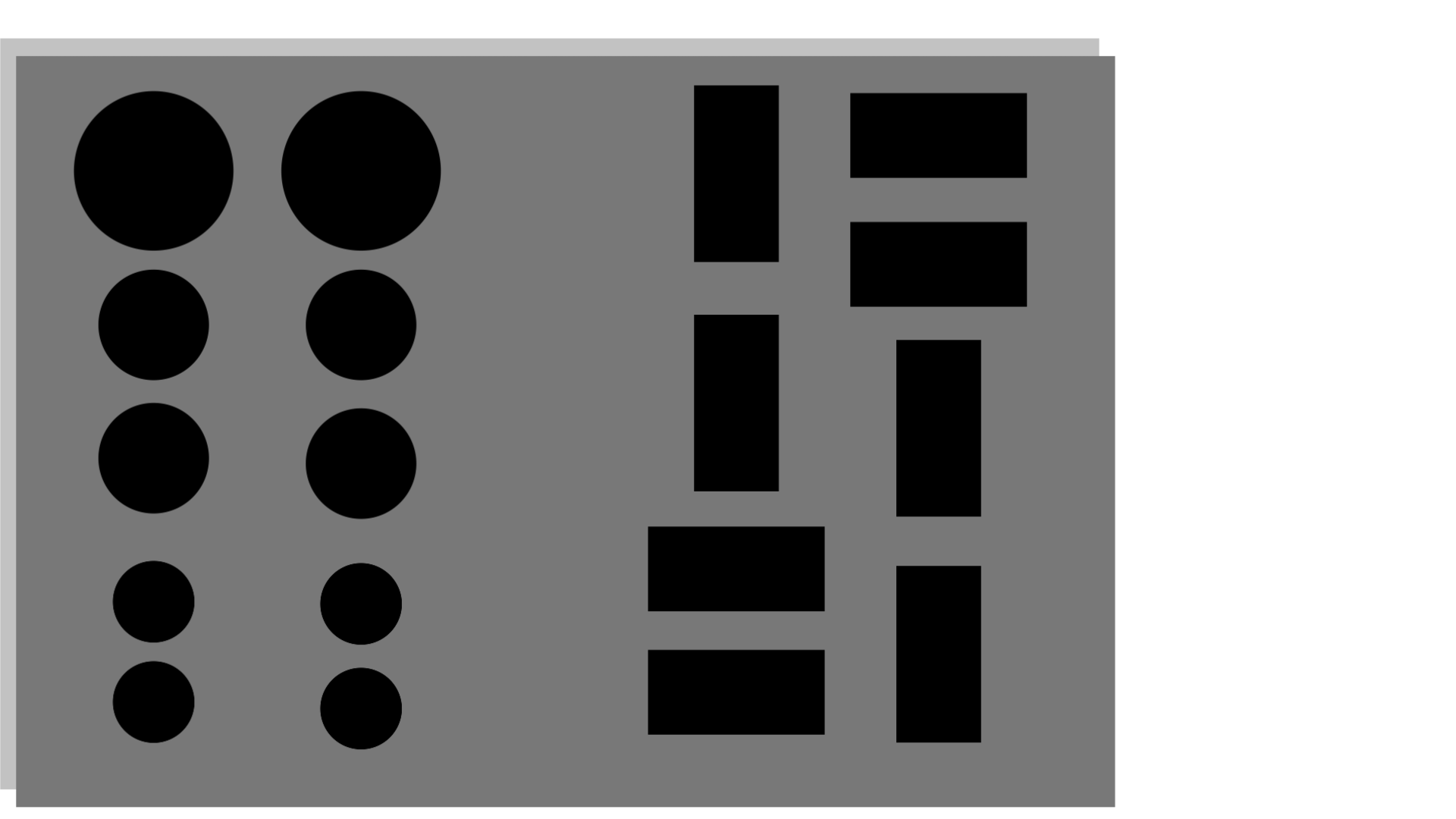
> 원본 이미지 trainA이다. 손상된 이미지 trainB 와 다르게 소자마다 그림자가 없는것을 확인할 수 있다.

> Generator가 최종적으로 생성하게 될 이미지이다. 손상된 이미지로부터 원본 이미지를 참고하여 그림자를 제거 즉, 복원하고자 한다. 실제 데이터를 참고하여 그림자가 절반정도 복원한 느낌을 표현하였다.
TRAIN 과정
위 코드를 참고하여 변경된 사항은 데이터셋 구성이다.
훈련을 위한 전체 코드는 다음과 같다.
import os
import glob
import random
import itertools
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy import asarray
from numpy.random import shuffle
from scipy.linalg import sqrtm
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.datasets.mnist import load_data
from skimage.transform import resize
from keras.datasets import cifar10
# scale an array of images to a new size
def scale_images(images, new_shape):
images_list = list()
for image in images:
# resize with nearest neighbor interpolation
new_image = resize(image, new_shape, 0)
# store
images_list.append(new_image)
return asarray(images_list)
# calculate frechet inception distance
def calculate_fid(model, images1, images2):
# calculate activations
act1 = model.predict(images1)
act2 = model.predict(images2)
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
# 흑백 이미지를 색상 이미지(R/G/B 채널)로 변환하기 위한 함수
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset_1(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/trainA") + "/*.bmp"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/trainB") + "/*.bmp"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
import cv2
import numpy as np
class ImageDataset2(Dataset):
def __init__(self, root, transforms_=None, mode="test"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/testA") + "/*.bmp"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/testB") + "/*.bmp"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
transforms_ = transforms.Compose([
transforms.Resize(int(256), Image.BICUBIC), # 이미지 크기를 조금 키우기
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 잔여 블록(Residual Block) 모듈 정의
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
# 채널(channel) 크기는 그대로 유지
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
nn.ELU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x)
# ResNet 기반의 생성자(Generator) 아키텍처
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0] # 입력 이미지의 채널 수: 3
# 초기 콘볼루션 블록(Convolution Block) 레이어
out_channels = 64
model = [nn.ReflectionPad2d(channels)]
model.append(nn.Conv2d(channels, out_channels, kernel_size=7))
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 다운샘플링(Downsampling)
for _ in range(2):
out_channels *= 2
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)) # 너비와 높이가 2배씩 감소
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 감소한 높이) X (4배 감소한 너비)]
# 인코더와 디코더의 중간에서 Residual Blocks 사용 (차원은 유지)
for _ in range(num_residual_blocks):
model.append(ResidualBlock(out_channels))
# 업샘플링(Upsampling)
for _ in range(2):
out_channels //= 2
model.append(nn.Upsample(scale_factor=2)) # 너비와 높이가 2배씩 증가
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)) # 너비와 높이는 그대로
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 증가한 높이) X (4배 증가한 너비)]
# 출력 콘볼루션 블록(Convolution Block) 레이어
model.append(nn.ReflectionPad2d(channels))
model.append(nn.Conv2d(out_channels, channels, kernel_size=7))
model.append(nn.Tanh())
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# 콘볼루션 블록(Convolution Block) 모듈 정의
def discriminator_block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1)] # 너비와 높이가 2배씩 감소
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.ELU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False), # 출력: [64 X 128 X 128]
*discriminator_block(64, 128), # 출력: [128 X 64 X 64]
*discriminator_block(128, 256), # 출력: [256 X 32 X 32]
*discriminator_block(256, 512), # 출력: [512 X 16 X 16]
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, kernel_size=4, padding=1) # 출력: [1 X 16 X 16]
)
# 최종 출력: [1 X (16배 감소한 높이) X (16배 감소한 너비)]
def forward(self, img):
return self.model(img)
# 생성자(generator)와 판별자(discriminator) 초기화
G_AB = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
G_BA = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
D_A = Discriminator(input_shape=(3, 256, 256))
D_B = Discriminator(input_shape=(3, 256, 256))
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
G_AB.load_state_dict(torch.load("/./PCB_AB.pt"))
G_BA.load_state_dict(torch.load("./PCB_BA.pt"))
D_A.load_state_dict(torch.load("./PCB_A.pt"))
D_B.load_state_dict(torch.load("./PCB_B.pt"))
# 가중치 초기화를 위한 함수 정의
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
#G_AB.apply(weights_init_normal)
#G_BA.apply(weights_init_normal)
#D_A.apply(weights_init_normal)
#D_B.apply(weights_init_normal)
#G_AB.eval();
#G_BA.eval();
#D_A.eval();
#D_B.eval();
# 이미지 버퍼(Buffer) 클래스
class ReplayBuffer:
def __init__(self, max_size=50):
self.max_size = max_size
self.data = []
# 새로운 이미지를 삽입하고, 이전에 삽입되었던 이미지를 반환하는 함수
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
# 아직 버퍼가 가득 차지 않았다면, 현재 삽입된 데이터를 반환
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
# 버퍼가 가득 찼다면, 이전에 삽입되었던 이미지를 랜덤하게 반환
else:
if random.uniform(0, 1) > 0.5: # 확률은 50%
i = random.randint(0, self.max_size - 1)
to_return.append(self.data[i].clone())
self.data[i] = element # 버퍼에 들어 있는 이미지 교체
else:
to_return.append(element)
return torch.cat(to_return)
# 시간이 지남에 따라 학습률(learning rate)을 감소시키는 클래스
class LambdaLR:
def __init__(self, n_epochs, decay_start_epoch):
self.n_epochs = n_epochs # 전체 epoch
self.decay_start_epoch = 200 # 학습률 감소가 시작되는 epoch
def step(self, epoch):
return 1.0 - max(0, epoch - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
# 가중치 초기화를 위한 함수 정의
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
n_epochs = 100000000 # 학습의 횟수(epoch) 설정
decay_epoch = 5 # 학습률 감소가 시작되는 epoch 설정
lr = 0.0002 # 학습률(learning rate) 설정
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(0.5, 0.999))
# 학습률(learning rate) 업데이트 스케줄러 초기화
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
import time
import torch
import numpy as np
sum_e = 0
sum_e_num = 0
e = 0
sample_interval = 100 # 몇 번의 배치(batch)마다 결과를 출력할 것인지 설정
lambda_cycle = 10 # Cycle 손실 가중치(weight) 파라미터
lambda_identity = 5 # Identity 손실 가중치(weight) 파라미터
# 이전에 생성된 이미지 데이터를 포함하고 있는 버퍼(buffer) 객체
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
start_time = time.time()
##############################dataset load###############################################
train_dataset_1 = ImageDataset_1("./PCB", transforms_=transforms_)
val_dataset = ImageDataset2("./PCB", transforms_=transforms_)
train_dataloader_1 = DataLoader(train_dataset_1, batch_size=1, shuffle=True, num_workers=1)
val_dataloader = DataLoader(val_dataset, batch_size=1, shuffle=True, num_workers=1)
##############################train start###############################################
model2 = InceptionV3(include_top=False, pooling='avg', input_shape=(256,256,3))
FFID = 100
for epoch in range(n_epochs):
'''if epoch == 1:
break'''
for i, batch in enumerate(train_dataloader_1):
# 모델의 입력(input) 데이터 불러오기
real_A = batch["B"].cuda()
real_B = batch["A"].cuda()
# 진짜(real) 이미지와 가짜(fake) 이미지에 대한 정답 레이블 생성 (너비와 높이를 16씩 나눈 크기)
real = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(1.0) # 진짜(real): 1
fake = torch.cuda.FloatTensor(real_A.size(0), 1, 16, 16).fill_(0.0) # 가짜(fake): 0
""" 생성자(generator)를 학습합니다. """
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity 손실(loss) 값 계산
loss_identity_A = criterion_identity(G_BA(real_A), real_A)
loss_identity_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_identity_A + loss_identity_B) / 2
# GAN 손실(loss) 값 계산
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
loss_GAN_AB = criterion_GAN(D_B(fake_B), real)
loss_GAN_BA = criterion_GAN(D_A(fake_A), real)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle 손실(loss) 값 계산
recover_A = G_BA(fake_B)
recover_B = G_AB(fake_A)
loss_cycle_A = criterion_cycle(recover_A, real_A)
loss_cycle_B = criterion_cycle(recover_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# 최종적인 손실(loss)
loss_G = loss_GAN + lambda_cycle * loss_cycle + lambda_identity * loss_identity
# 생성자(generator) 업데이트
loss_G.backward()
optimizer_G.step()
""" 판별자(discriminator) A를 학습합니다. """
optimizer_D_A.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_A(real_A), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_A = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A.detach()), fake)
# 최종적인 손실(loss)
loss_D_A = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_A.backward()
optimizer_D_A.step()
""" 판별자(discriminator) B를 학습합니다. """
optimizer_D_B.zero_grad()
# Real 손실(loss): 원본 이미지를 원본으로 판별하도록
loss_real = criterion_GAN(D_B(real_B), real)
# Fake 손실(loss): 가짜 이미지를 가짜로 판별하도록
fake_B = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B.detach()), fake)
# 최종적인 손실(loss)
loss_D_B = (loss_real + loss_fake) / 2
# 판별자(discriminator) 업데이트
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
done = epoch * len(train_dataloader_1) + i
if done % sample_interval == 0:
G_AB.eval()
G_BA.eval()
imgs = next(iter(val_dataloader)) # 5개의 이미지를 추출해 생성
real_A = imgs["B"].cuda()
real_B = imgs["A"].cuda()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
# X축을 따라 각각의 그리디 이미지 생성
real_A = make_grid(real_A, normalize=True)
real_B = make_grid(real_B, normalize=True)
fake_A = make_grid(fake_A, normalize=True)
fake_B = make_grid(fake_B, normalize=True)
# 각각의 격자 이미지를 높이(height)를 기준으로 연결하기
#image_grid = torch.cat((real_A, fake_B, real_B, fake_A), 1)
#save_image(fake_B, f"./fake_B.png", normalize=False)
#save_image(real_B, f"./real_B.png", normalize=False)
#print('Loaded', fake_B.shape, real_B.shape)
# convert integer to floating point values
fake_B = fake_B.cpu().numpy()
real_B = real_B.cpu().numpy()
fake_B = fake_B.astype('float32')
real_B = real_B.astype('float32')
# resize images
fake_B = scale_images(fake_B, (256,256,3))
real_B = scale_images(real_B, (256,256,3))
#print('Scaled', fake_B.shape, real_B.shape)
# pre-process images
fake_B = preprocess_input(fake_B)
real_B = preprocess_input(real_B)
# calculate fid
fid = calculate_fid(model2, fake_B, real_B)
if FFID > fid:
FFID = fid
print('FID: %.3f' % fid)
torch.save(G_AB.state_dict(), f"./PCB_AB.pt")
torch.save(G_BA.state_dict(), f"./PCB_BA.pt")
torch.save(D_A.state_dict(), f"./PCB_A.pt")
torch.save(D_B.state_dict(), f"./PCB_B.pt")
print("Model 갱신!")
# 학습률(learning rate)
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
print(f"[Epoch {epoch}/{n_epochs}] [Elapsed time: {time.time() - start_time:.2f}s]")> torch.load 로 경로를 수정하거나 주석처리를 진행하면 된다. (이미 훈련된 모델이 있다면 경로 수정)
> torch.save 로 경로를 설정해 모델을 저장한다.
> train / val dataset 에서는 데이터셋의 경로를 넣어준다. ( 형식은 코드를 수정할 수 있지만, 기본값은 데이터셋파일 > train / test > trainA / trainB , testA / testB ) *** 주의할 점은 데이터셋 형식이 bmp 라는 것이다. 사용자에 맞게 수정 가능하다. 모든 bmp를 png, jpg... 으로 바꾸면 된다 ***
> 이전의 예제 데이터와 달리 우리는 이미지 복원이 잘 되었는지 확인을 위해 FID 를 계산하여 보여준다. 이는 낮을수록 좋은 수치이다.

> 손상된 이미지 사진이다. 그림자 영역부분을 묘사한 것이며 그림자를 없애는걸 복원의 목표로 한다.
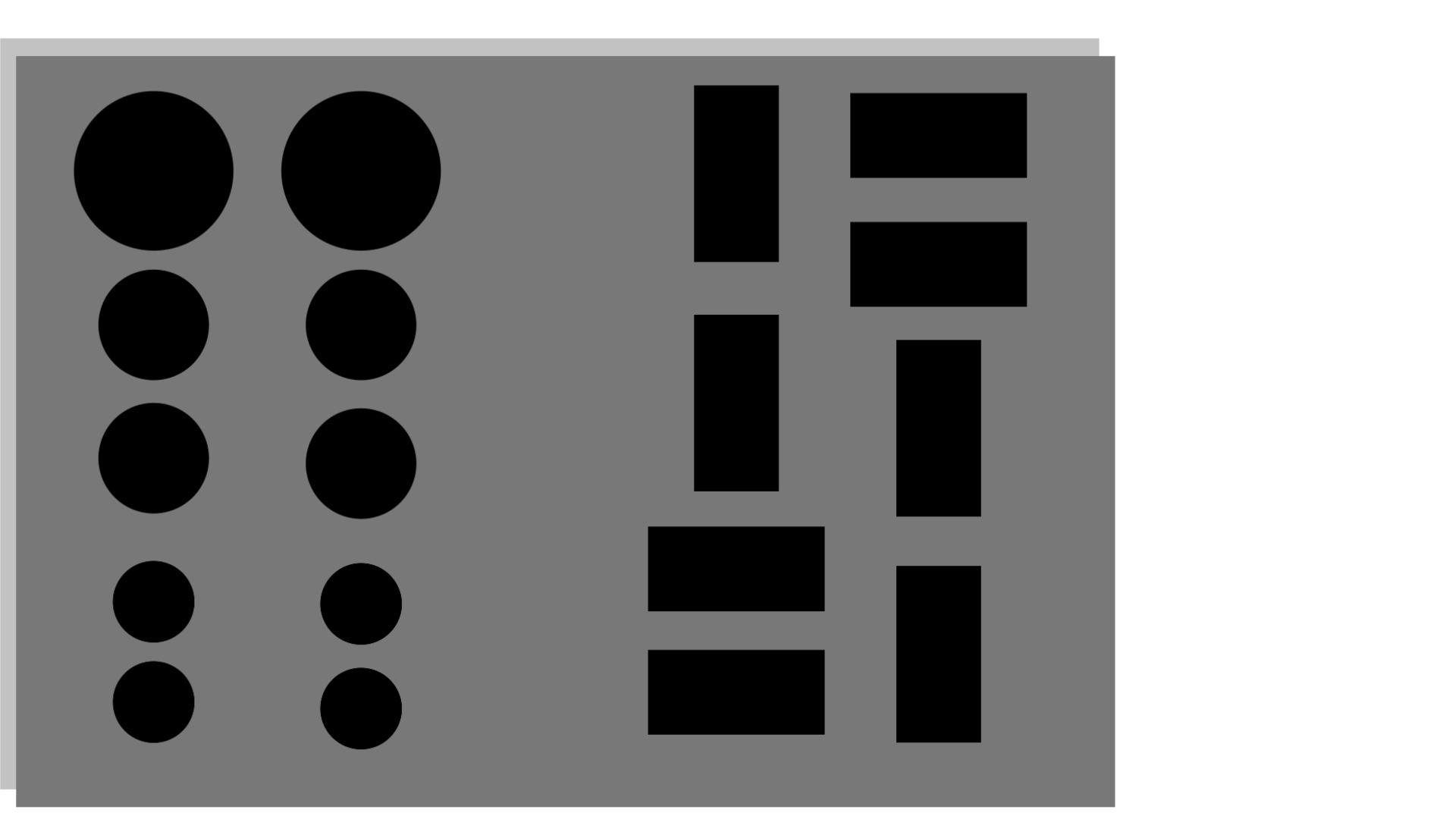

> 왼쪽 사진이 원본 이미지 real_B 이고 그림자가 없는것을 확인할 수 있다, 오른쪽 사진이 복원된 이미지 fake_B 이고 어느정도 그림자가 복원되었다는걸 표현하고 있다.
TEST 과정
import os
import glob
import random
import itertools
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from scipy.linalg import sqrtm
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset2(Dataset):
def __init__(self, root, transforms_=None, mode="test"):
self.transform = transforms_
self.files_A = sorted(glob.glob(os.path.join(root, f"{mode}/testA") + "/*.bmp"))
self.files_B = sorted(glob.glob(os.path.join(root, f"{mode}/testB") + "/*.bmp"))
def __getitem__(self, index):
img_A = Image.open(self.files_A[index % len(self.files_A)])
img_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]) # img_B는 랜덤하게 샘플링
# 만약 흑백(grayscale) 이미지라면 RGB 채널 이미지로 변환
if img_A.mode != "RGB":
img_A = to_rgb(img_A)
if img_B.mode != "RGB":
img_B = to_rgb(img_B)
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
transforms_ = transforms.Compose([
transforms.Resize(int(256), Image.BICUBIC), # 이미지 크기를 조금 키우기
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
val_dataset1 = ImageDataset2("/home/a/Desktop/김태정/ROBOTICS_FILE/MOIRE/논문용_phase_map_PCB/PCB1", transforms_=transforms_)
val_dataloader1 = DataLoader(val_dataset1, batch_size=1, shuffle=True, num_workers=1)
# 잔여 블록(Residual Block) 모듈 정의
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
# 채널(channel) 크기는 그대로 유지
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
nn.ELU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, kernel_size=3),
nn.InstanceNorm2d(in_channels),
)
def forward(self, x):
return x + self.block(x)
# ResNet 기반의 생성자(Generator) 아키텍처
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0] # 입력 이미지의 채널 수: 3
# 초기 콘볼루션 블록(Convolution Block) 레이어
out_channels = 64
model = [nn.ReflectionPad2d(channels)]
model.append(nn.Conv2d(channels, out_channels, kernel_size=7))
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 다운샘플링(Downsampling)
for _ in range(2):
out_channels *= 2
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)) # 너비와 높이가 2배씩 감소
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 감소한 높이) X (4배 감소한 너비)]
# 인코더와 디코더의 중간에서 Residual Blocks 사용 (차원은 유지)
for _ in range(num_residual_blocks):
model.append(ResidualBlock(out_channels))
# 업샘플링(Upsampling)
for _ in range(2):
out_channels //= 2
model.append(nn.Upsample(scale_factor=2)) # 너비와 높이가 2배씩 증가
model.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)) # 너비와 높이는 그대로
model.append(nn.InstanceNorm2d(out_channels))
model.append(nn.ELU(inplace=True))
in_channels = out_channels
# 출력: [256 X (4배 증가한 높이) X (4배 증가한 너비)]
# 출력 콘볼루션 블록(Convolution Block) 레이어
model.append(nn.ReflectionPad2d(channels))
model.append(nn.Conv2d(out_channels, channels, kernel_size=7))
model.append(nn.Tanh())
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# 콘볼루션 블록(Convolution Block) 모듈 정의
def discriminator_block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1)] # 너비와 높이가 2배씩 감소
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.ELU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False), # 출력: [64 X 128 X 128]
*discriminator_block(64, 128), # 출력: [128 X 64 X 64]
*discriminator_block(128, 256), # 출력: [256 X 32 X 32]
*discriminator_block(256, 512), # 출력: [512 X 16 X 16]
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, kernel_size=4, padding=1) # 출력: [1 X 16 X 16]
)
# 최종 출력: [1 X (16배 감소한 높이) X (16배 감소한 너비)]
def forward(self, img):
return self.model(img)
# 시간이 지남에 따라 학습률(learning rate)을 감소시키는 클래스
class LambdaLR:
def __init__(self, n_epochs, decay_start_epoch):
self.n_epochs = n_epochs # 전체 epoch
self.decay_start_epoch = decay_start_epoch # 학습률 감소가 시작되는 epoch
def step(self, epoch):
return 1.0 - max(0, epoch - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
# 생성자(generator)와 판별자(discriminator) 초기화
G_AB = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
G_BA = GeneratorResNet(input_shape=(3, 256, 256), num_residual_blocks=9)
D_A = Discriminator(input_shape=(3, 256, 256))
D_B = Discriminator(input_shape=(3, 256, 256))
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
G_AB.load_state_dict(torch.load("./PCB_AB.pt"))
G_BA.load_state_dict(torch.load("./PCB_BA.pt"))
D_A.load_state_dict(torch.load("./PCB_A.pt"))
D_B.load_state_dict(torch.load("./PCB_B.pt"))
G_AB.eval();
G_BA.eval();
D_A.eval();
D_B.eval();
# 손실 함수(loss function)
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
n_epochs = 200 # 학습의 횟수(epoch) 설정
decay_epoch = 5 # 학습률 감소가 시작되는 epoch 설정
lr = 0.0002 # 학습률(learning rate) 설정
# 생성자와 판별자를 위한 최적화 함수
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(0.5, 0.999))
# 학습률(learning rate) 업데이트 스케줄러 초기화
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(n_epochs, decay_epoch).step)
max_acc = 0
i = 0
import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy import asarray
from numpy.random import shuffle
from scipy.linalg import sqrtm
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.datasets.mnist import load_data
from skimage.transform import resize
from keras.datasets import cifar10
# scale an array of images to a new size
def scale_images(images, new_shape):
images_list = list()
for image in images:
# resize with nearest neighbor interpolation
new_image = resize(image, new_shape, 0)
# store
images_list.append(new_image)
return asarray(images_list)
# calculate frechet inception distance
def calculate_fid(model, images1, images2):
# calculate activations
act1 = model.predict(images1)
act2 = model.predict(images2)
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
while(1):
if i == 1:
break
e = 0
from PIL import Image
imgs = next(iter(val_dataloader1))
real_A = imgs["B"].cuda()
real_B = imgs["A"].cuda()
fake_B = G_AB(real_A)
fake_A = G_BA(real_B)
fake_B = make_grid(fake_B, normalize=True)
real_B = make_grid(real_B, normalize=True)
save_image(fake_B, f"fake_B.bmp", normalize=False)
save_image(real_B, f"real_B.bmp", normalize=False)
print(fake_B.size())
model2 = InceptionV3(include_top=False, pooling='avg', input_shape=(256,256,3))
print('Loaded', fake_B.shape, real_B.shape)
# convert integer to floating point values
fake_B = fake_B.cpu().numpy()
real_B = real_B.cpu().numpy()
fake_B = fake_B.astype('float32')
real_B = real_B.astype('float32')
# resize images
fake_B = scale_images(fake_B, (256,256,3))
real_B = scale_images(real_B, (256,256,3))
print('Scaled', fake_B.shape, real_B.shape)
# pre-process images
fake_B = preprocess_input(fake_B)
real_B = preprocess_input(real_B)
# calculate fid
fid = calculate_fid(model2, fake_B, real_B)
print('FID: %.3f' % fid)
i+=1> 말 예제와 비슷한 구성이지만, 역시나 FID 가 추가되었다.
> 원본 이미지와 손상된 이미지, 복원된 이미지가 존재하고, 우리는 fake_B 복원된 이미지와 real_B 원본 이미지와의 FID 계산을 통해 복원이 잘 되었는지를 판별할 수 있다.

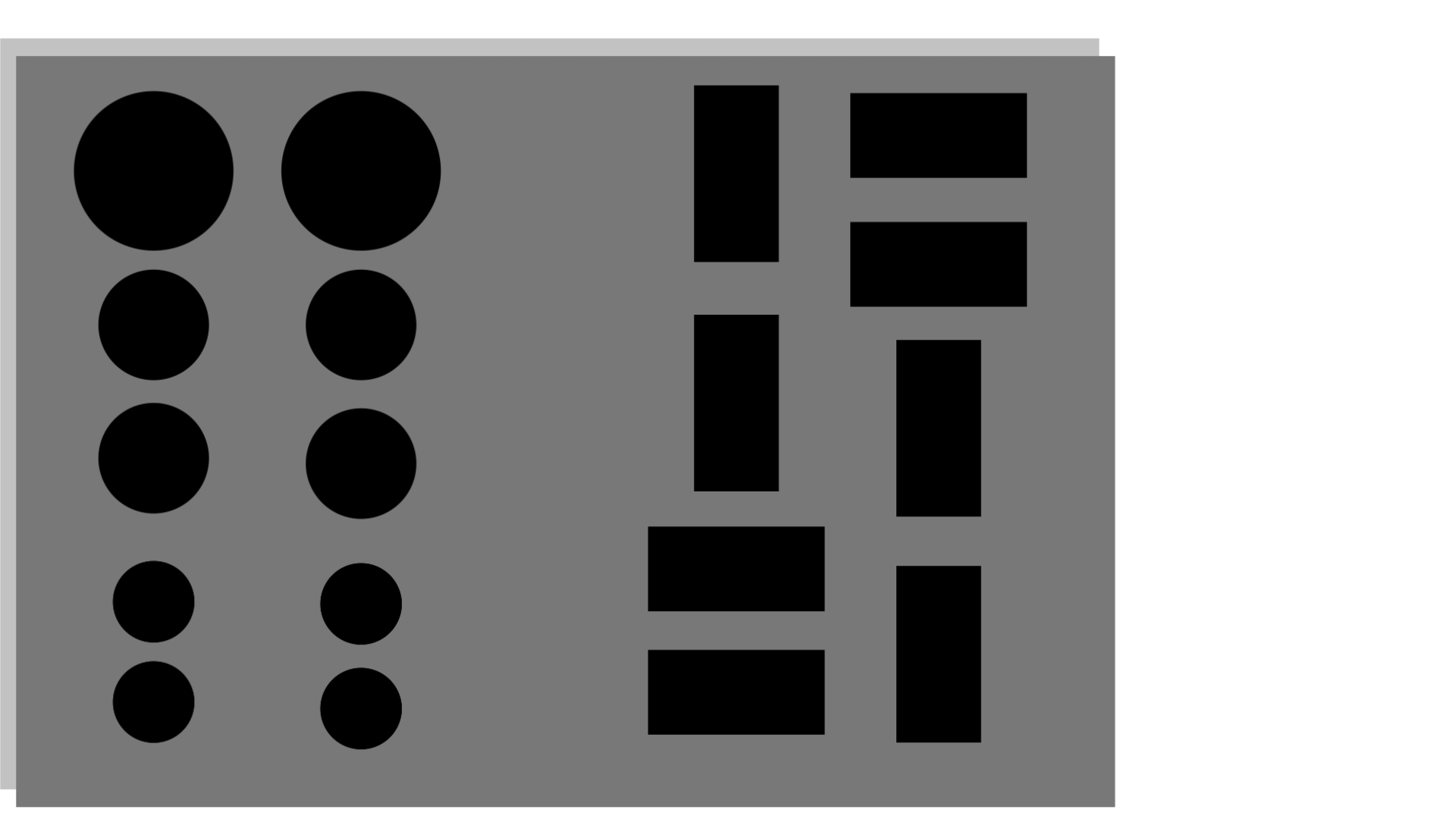

> train과 동일하게 좌측의 손상된 이미지에서 우측의 원본 이미지로 복원하고자, 하단의 복원된 이미지를 얻었다.
else
기존의 연구 목표였던 이미지 복원에 대한 결과물을 확인하였다.
요약하자면, 이미지 속 그림자를 제거 및 복원하는것을 목표로 하였고, CycleGAN 특성상 이미지의 스타일을 변경할 수 있다는 점을 참고하였다.
하지만, CycleGAN 의 경우 그림자부분을 복원하는 것뿐 아니라 그림자가 아닌 전체적인 이미지를 생성하다보니, 손상된 이미지에 대한 전체적인 특징을 잃는다는 단점이 있다.
이를 해결하고자 Image Inpainting 개념을 도입하였고, 이에 대한 연구를 계속해 나가고자 한다.
'ML&DL > GAN' 카테고리의 다른 글
| #3 DCGAN (Generative Adversarial Networks) - CelebA, 자체 제작 데이터셋 실습 (0) | 2023.08.02 |
|---|---|
| #2 GAN (Generative Adversarial Networks) - MNIST, CelebA, 자체 제작 데이터셋 실습 (0) | 2023.08.01 |
| #1 GAN (Generative Adversarial Networks) - 전체적인 틀 (4) | 2023.08.01 |


